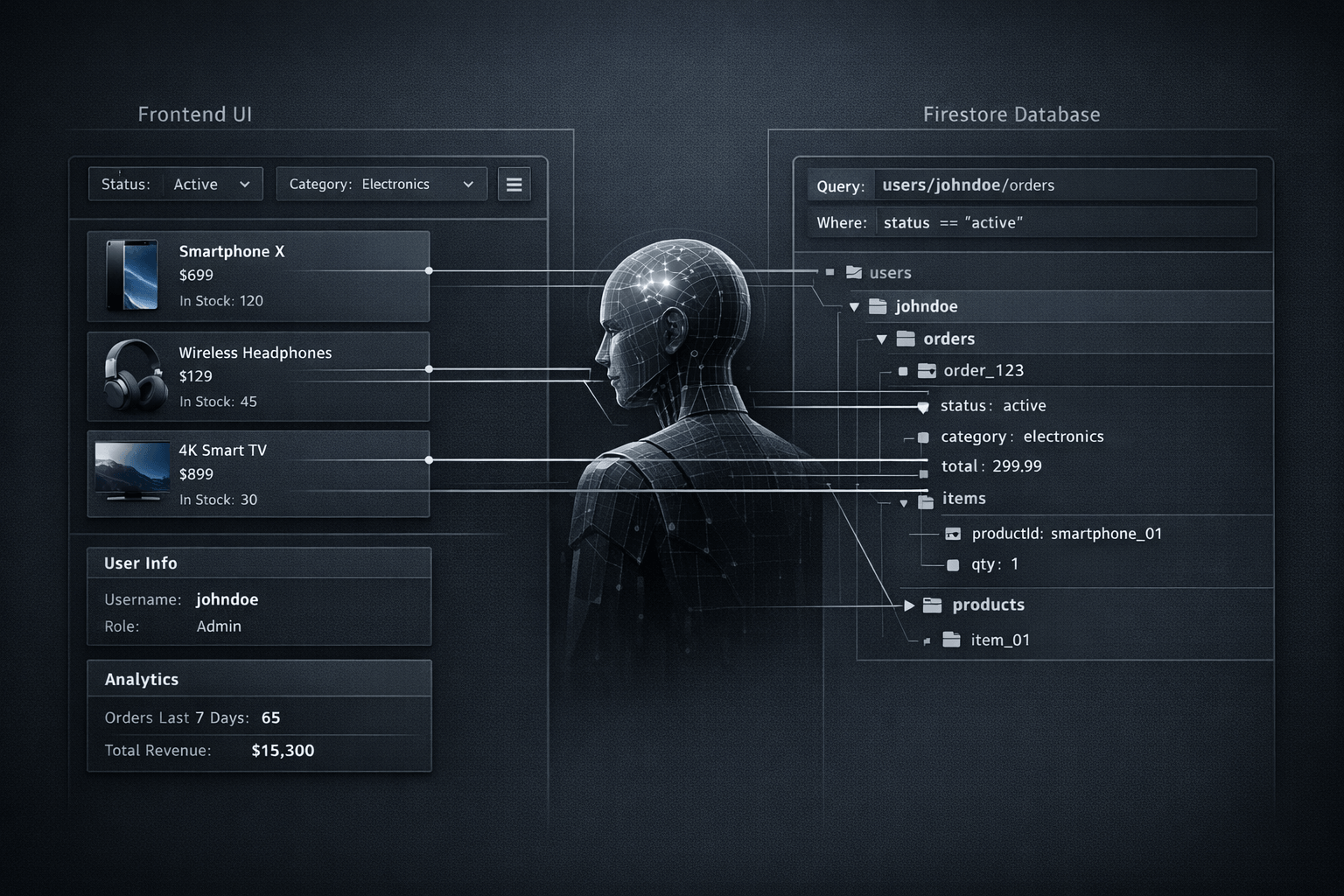
Teams working on Flutter and Firebase apps often debug from the surface inward. They inspect widgets, network calls, local models and state management first, then try to infer what the backend probably looks like. That can be useful, but it is still guesswork. In many cases, the faster route is to inspect the real database shape directly. When an agent has access to real database context through Firestore-aware tools, it can reason about frontend behavior against the source of truth rather than against assumptions.
Summary
The core point is simple: backend inference from frontend code has limits. Firebase documentation describes Cloud Firestore as a document database organized around collections, documents and subcollections, and it explicitly allows flexible structures that do not depend on a fixed schema. That flexibility is useful in product development, but it also means the frontend does not always tell the whole story. Reading the real Firestore structure helps reveal collection paths, nested documents, field naming drift and subcollection boundaries that UI code alone may not expose.
What happened
A growing number of AI-assisted development workflows are moving beyond static code inspection and toward direct environmental context. For Firebase projects, that means it is not enough to scan a Flutter screen and infer the backend contract from model classes, repository methods or hand-written docs. The more effective pattern is to combine frontend reasoning with targeted inspection of the live or sampled Firestore structure. Firebase's own data model documentation highlights that documents can contain nested objects and subcollections, while separate guidance on data structure choices explains that different layouts have different tradeoffs for scale, queryability and complexity.
Why it matters
This matters because many implementation and debugging errors come from mismatched expectations, not from syntax. A Flutter screen may expect users/{id}/profiles/main while the database uses userProfiles/{id}. A UI may read displayName while stored documents use name. A list view may assume embedded arrays when the project has already moved to subcollections for scalability. None of those mistakes are unusual, and none are easy to settle by reading frontend code in isolation.
The practical gain is not that the agent becomes more confident. It is that the agent has fewer reasons to be wrong.
Real Firestore context reduces guesswork
Firestore documentation is clear that documents live inside collections, may include subcollections, and do not enforce a rigid relational schema. That flexibility is exactly why direct inspection is valuable. An agent that can read the real structure can check whether a collection exists, whether a field appears consistently, whether subcollections are being used, and whether the data shape supports the query pattern assumed by the frontend. In practice, this reduces speculative fixes and shortens the loop between diagnosis and implementation.
It also helps with schema drift. Teams often evolve from nested fields to root-level collections, or from one naming convention to another, without fully updating every repository, serializer or screen. When the actual database is visible, these drifts become concrete instead of hypothetical.
Frontend and backend reasoning should stay aligned
This does not mean frontend analysis stops being useful. Quite the opposite: the most reliable workflow combines both sides. The frontend explains intent, user flow and expected data usage. The backend context confirms what is really stored and how it is structured. In a Firestore-backed Flutter app, that combined view helps distinguish between a rendering bug, a query bug, a path mismatch and a stale assumption baked into client code.
Firebase's guidance on choosing a data structure also underscores why this alignment matters. Nested data, subcollections and root collections each solve different problems. If a team changes its structure for scalability or querying reasons, but the UI keeps reasoning as if the old structure still exists, the resulting bugs can look random from the frontend while being obvious from the database side.
Connection to Nic Hyper Flow
This is where Nic Hyper Flow becomes relevant in a measured, practical way. Its Firestore tools are useful not because they add abstract database awareness, but because they let the agent inspect real project context directly. For teams building with Flutter and Firebase, that means the agent can compare frontend expectations with observed Firestore structure, notice likely mismatches and debug with less inference. The value is especially clear in cases where repository code, documentation and database reality have drifted apart.
In other words, Firestore-aware debugging is not just about reading more information. It is about reading the right information early enough to avoid wasting time on the wrong theory.
Conclusion
For AI agents and human developers alike, the lesson is straightforward: if the goal is to understand how a Firebase application actually behaves, the real Firestore structure is a better source of truth than frontend inference alone. Frontend code still provides essential context, but direct schema and collection visibility makes reasoning more grounded. In practice, that tends to improve implementation accuracy, mismatch detection and debugging quality.
Sources
1. Firebase Documentation — Cloud Firestore Data Model:
https://firebase.google.com/docs/firestore/data-model
2. Firebase Documentation — Choose a Data Structure:
https://firebase.google.com/docs/firestore/manage-data/structure-data
Read pages for this article: the two Firebase documentation pages above were consulted directly before writing.